La redondance des données en informatique
Introduction
En informatique, la redondance des données désigne l'ensemble des techniques consistant à dupliquer ou répartir des informations sur plusieurs supports afin d'améliorer la fiabilité et la disponibilité du stockage.
En d'autres termes, au lieu de stocker chaque donnée sur un seul disque, on utilise plusieurs disques de façon à pouvoir tolérer la panne de l'un d'entre eux sans perte de données. Cette stratégie augmente la résilience face aux défaillances matérielles : si un support tombe en panne, les données peuvent être reconstruites à partir des autres copies ou informations redondantes. Outre la tolérance aux pannes, certaines formes de redondance peuvent aussi améliorer les performances de lecture/écriture ou la capacité globale de stockage. Toutefois, il est important de noter que la redondance n'est pas une sauvegarde : elle protège contre la perte due à une panne matérielle, mais n'empêche pas les erreurs humaines (fichiers effacés par inadvertance, corruption logicielle, etc.) ni les sinistres majeurs -- des sauvegardes externes restent donc indispensables.
La redondance des données est couramment implémentée par les systèmes de stockage RAID (Redundant Array of Independent Disks -- matrice redondante de disques). Le principe du RAID est de combiner plusieurs disques durs (ou SSD) en une « grappe » (array) apparaissant comme un seul volume logique, mais offrant une tolérance aux pannes et/ou de meilleures performances. Il existe plusieurs niveaux de RAID numérotés (RAID 0, 1, 5, 6, 10, etc.), chacun ayant une architecture de redondance différente. D'autres technologies connexes incluent les déclinaisons du RAID dans certains systèmes de fichiers modernes (par ex. RAID-Z de ZFS) ou des schémas de codes correcteurs plus avancés (parités multiples, double parité, triple parité).
Dans cet article, nous allons passer en revue les principaux types de redondance : les niveaux de RAID les plus courants (y compris RAID 0, 1, 5, 6, 10), les variantes comme le RAID-Z, ainsi que les notions de miroir et de parité (simple, double, triple). Nous comparerons ensuite ces systèmes de redondance à travers les systèmes de fichiers les plus répandus (ZFS, Btrfs, ext4, NTFS, XFS, APFS...), en expliquant pour chacun s'il prend en charge nativement la redondance ou s'il dépend d'un gestionnaire RAID sous-jacent. Des tableaux récapitulatifs en fin de document synthétiseront les différences en termes de niveau de protection, de performances, de tolérance de panne et de complexité de mise en œuvre.
Les différentes technologies de redondance (RAID et parités)
RAID 0 : entrelacement (striping) sans redondance
Le RAID 0 (zéro) répartit les données en blocs écrits à la suite sur plusieurs disques à tour de rôle (mise en bande ou striping). Chaque disque ne contient donc qu'une partie des données, ce qui accroît la vitesse de lecture/écriture : les opérations d'I/O peuvent s'effectuer en parallèle sur les disques, augmentant le débit global proportionnellement au nombre de disques. En revanche, le RAID 0 ne fournit aucune redondance ni tolérance de panne : la défaillance d'un seul disque entraîne la perte de l'ensemble des données du volume, car chaque fichier est « morcelé » sur tous les disques. Le RAID 0 est ainsi utilisé uniquement lorsque la performance prime sur la fiabilité, par exemple pour du stockage temporaire ou des caches dont la perte serait sans conséquence. La capacité totale d'un RAID 0 est la somme des capacités des disques (idéalement de tailles identiques, sinon la plus petite taille alignera la capacité).
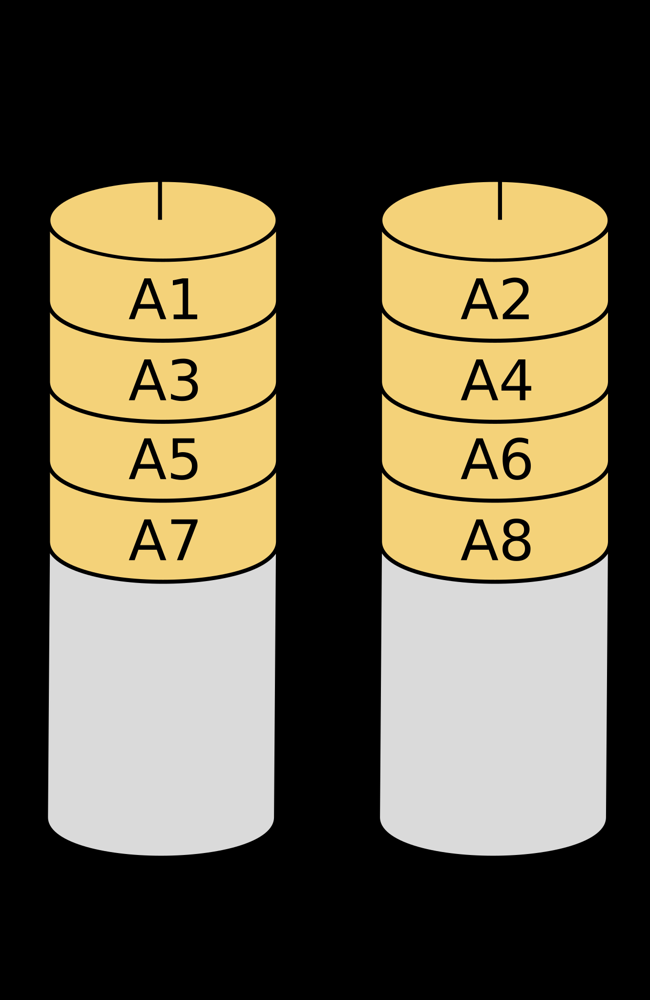
Schéma de principe d'un RAID 0 à deux disques (les blocs de données A1, A3, A5, A7 sont écrits sur le disque 0 tandis que A2, A4, A6, A8 le sont sur le disque 1). Le RAID 0 améliore les performances en alternant les blocs entre les disques, mais ne propose aucune redondance : la perte d'un disque rend le volume inutilisable.
RAID 1 : miroir (mirroring)
Le RAID 1 implémente la redondance par miroir. Deux disques (ou plus) contiennent en permanence exactement les mêmes données, comme une copie miroir l'un de l'autre. Chaque écritures est reproduite à l'identique sur tous les disques du miroir, et chaque lecture peut être servie par n'importe lequel des disques contenant la donnée. Ainsi, si l'un des disques tombe en panne, les autres possèdent toujours une copie intacte -- le système continue de fonctionner tant qu'au moins un disque est opérationnel. Cette solution offre un excellent niveau de protection des données (tolérance à au moins une panne) au prix d'un coût de stockage élevé : la capacité utile correspond seulement à la taille d'un des disques (puisque chaque donnée est dupliquée sur 2 disques ou plus). Par exemple, un miroir de deux disques de 4 To fournit 4 To utiles (chaque bit étant écrit deux fois). En contrepartie, les performances en lecture peuvent bénéficier du parallélisme (on peut lire en load balancing sur les deux disques pour augmenter le débit), tandis que les écritures subissent un léger impact (il faut écrire les données sur chaque disque du miroir, sans toutefois de calcul complexe). Le RAID 1 est simple à mettre en œuvre et très apprécié pour les systèmes critiques nécessitant une haute disponibilité avec une configuration peu complexe.
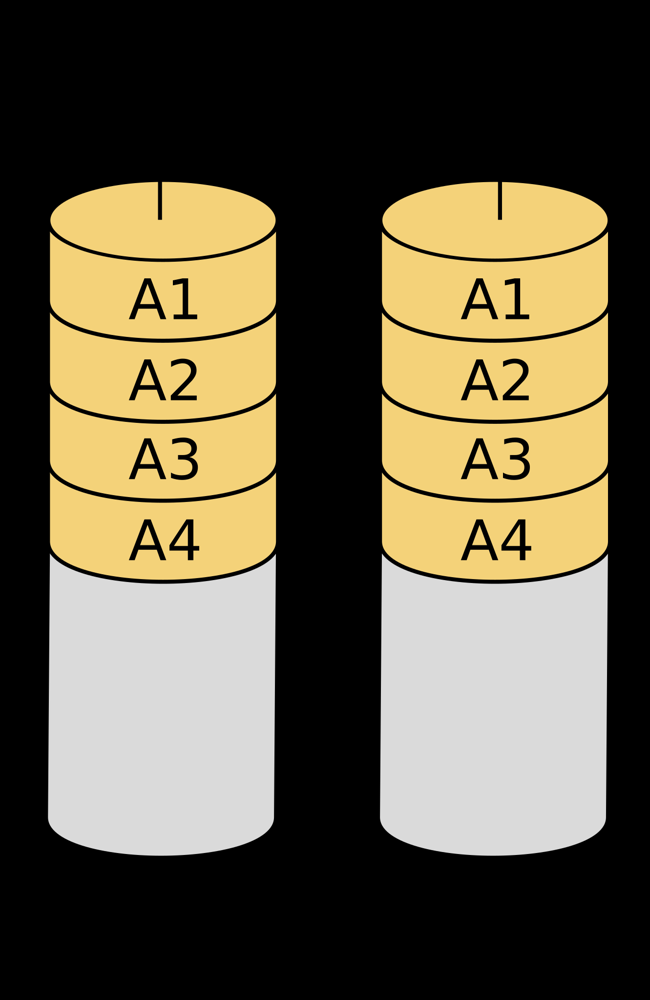
Illustration du fonctionnement du RAID 1 (miroir) : à gauche et à droite, deux disques contiennent chacun une copie identique des blocs de données A1...A4. Chaque donnée est dupliquée sur les deux unités, assurant la continuité de service si l'une d'elles tombe en panne. La capacité utile = capacité du plus petit disque (ici 100% de redondance, 50% d'espace utile).
RAID 5 : parité simple distribuée
Le RAID 5 est l'un des niveaux les plus utilisés en entreprise et dans les NAS. Il combine la répartition des données en bandes (striping, comme le RAID 0) avec de la parité distribuée sur l'ensemble des disques. Concrètement, un RAID 5 nécessite au minimum 3 disques. Les données sont découpées en bandes (par exemple de 64 Ko) écrites sur N-1 disques, tandis que le dernier disque de chaque bande stocke un bloc de parité P calculé par une opération binaire (typiquement un XOR) sur les données de la bande. Ce bloc de parité n'est pas toujours sur le même disque : il est réparti tour à tour sur chaque disque de la grappe, d'où l'expression parité répartie. Ainsi, il n'y a pas de « disque dédié à la parité » fixe (contrairement au RAID 4), ce qui équilibre les écritures entre tous les disques.
En fonctionnement normal, un RAID 5 offre une tolérance à la panne d'un seul disque : si l'un des disques tombe en panne, ses données manquantes peuvent être recalculées à la volée en utilisant les données des autres disques plus le bloc de parité correspondant (puisque dans un XOR, P ⊕ Data = Missing Data). La reconstruction d'un disque défaillant consiste ainsi à lire l'intégralité des données des disques restants pour recomposer les blocs perdus, ce qui peut être long sur de très gros volumes. Durant cette phase critique, si un second disque venait à flancher, les données seraient perdues (RAID 5 ne supporte qu'une panne à la fois). C'est pourquoi le RAID 5 est adapté pour des grappes de taille modérée : avec de nombreux disques et de grandes capacités, la fenêtre de reconstruction prolongée augmente le risque statistique d'une deuxième panne simultanée.
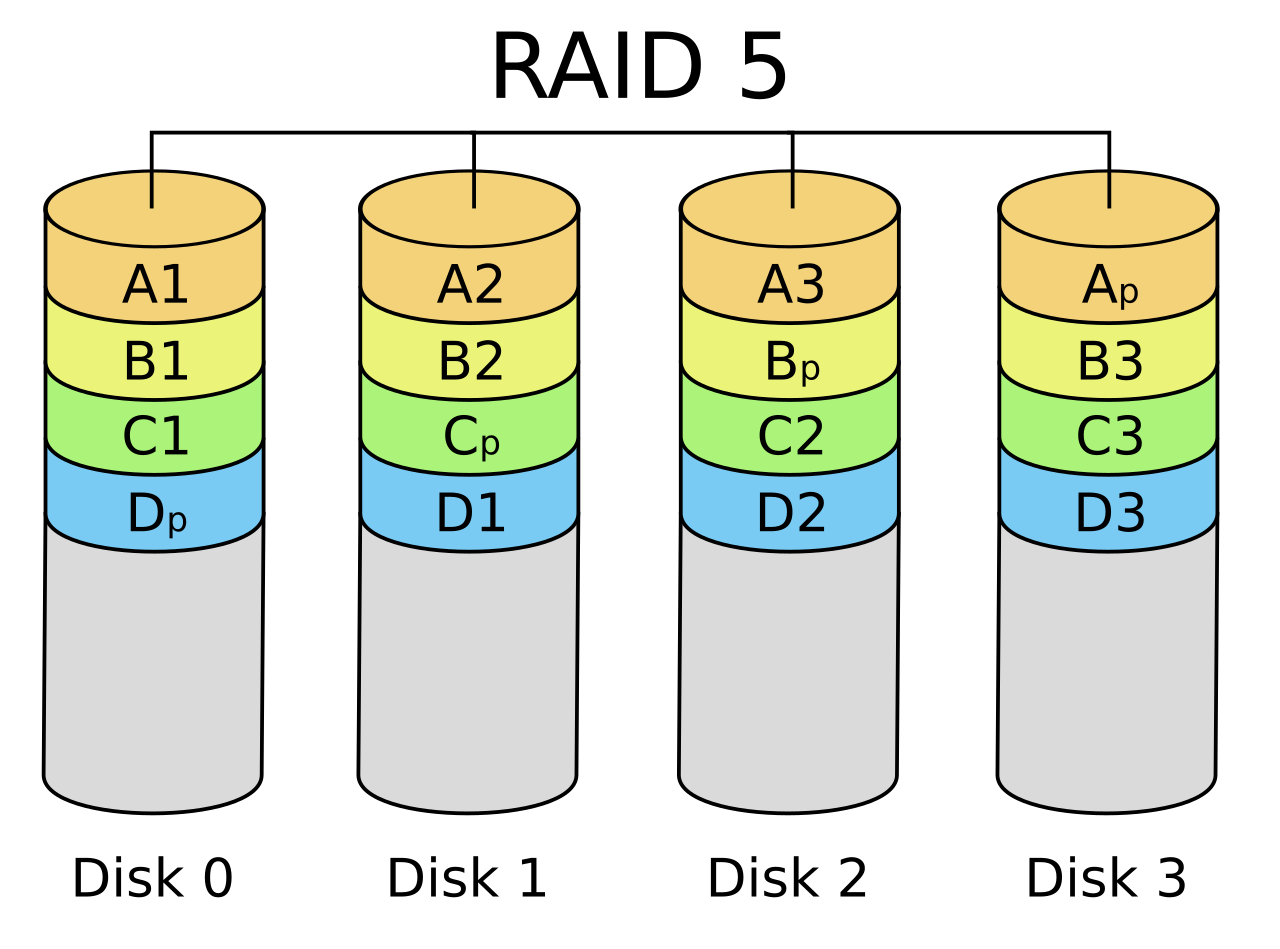
(Source : Wikipedia.org)
En termes de performances, un RAID 5 en lecture se comporte proche d'un RAID 0 (lecture en parallèle sur N-1 disques, le bloc de parité étant ignoré sauf en cas de panne). En écriture, en revanche, il y a un surcoût : il faut recalculer et mettre à jour le bloc de parité à chaque modification. Pour une petite écriture affectant une partie d'une bande, le contrôleur doit en général lire l'ancienne donnée et l'ancienne parité afin de calculer la nouvelle parité, puis écrire la donnée modifiée et la nouvelle parité (write penalty). Ce processus ralenti les écritures aléatoires intensives sur RAID 5. Malgré cela, le RAID 5 reste un bon compromis offrant à la fois sécurité (un disque de tolérance), capacité efficace (seulement l'équivalent d'un disque est « perdu » pour la parité) et débit en lecture proche du maximal. Par exemple, une grappe de 5 disques de 2 To en RAID 5 offrira ~8 To utiles (4 disques de données + 1 disque équivalent de parité) et pourra tolérer la perte de l'un d'entre eux.
RAID 6 : double parité
Le RAID 6 étend le principe du RAID 5 en ajoutant un second bloc de parité indépendante par bande de données. Il nécessite au minimum 4 disques et peut être vu comme un RAID 5 à double parité : chaque bande de données comporte deux informations de parité calculées selon des algorithmes différents, généralement à l'aide de codes de Reed-Solomon sur un Galois Field (une parité de type Q en plus de la parité P de type XOR). Grâce à ces deux parités, un RAID 6 peut survivre à la panne simultanée de deux disques sans perte de données. C'est un niveau de redondance plus élevé, justifié lorsque la taille des disques et le nombre de disques rendent trop risqué un RAID 5.
En contrepartie, le RAID 6 subit un surcoût de calcul et de stockage plus important. La capacité utile est amputée de l'équivalent de 2 disques (par exemple, 6 disques de 4 To en RAID 6 fournissent 4×4 To = 16 To utiles, les deux disques restants étant utilisés pour stocker les deux parités). Les performances en lecture restent bonnes (similaires à RAID 5), mais les écritures sont encore un peu plus pénalisées car il faut calculer et écrire deux parités différentes pour chaque bande de données. De plus, le temps de reconstruction après une panne est plus long qu'en RAID 5 car il faut gérer deux calculs de parité. Néanmoins, le RAID 6 apporte une sécurité appréciable dans les baies de grande capacité, où la reconstruction d'un disque de plusieurs To peut durer des heures, période durant laquelle un second disque pourrait lâcher. Avec le RAID 6, les données resteraient intègres même dans ce cas (tolérance à deux pannes).
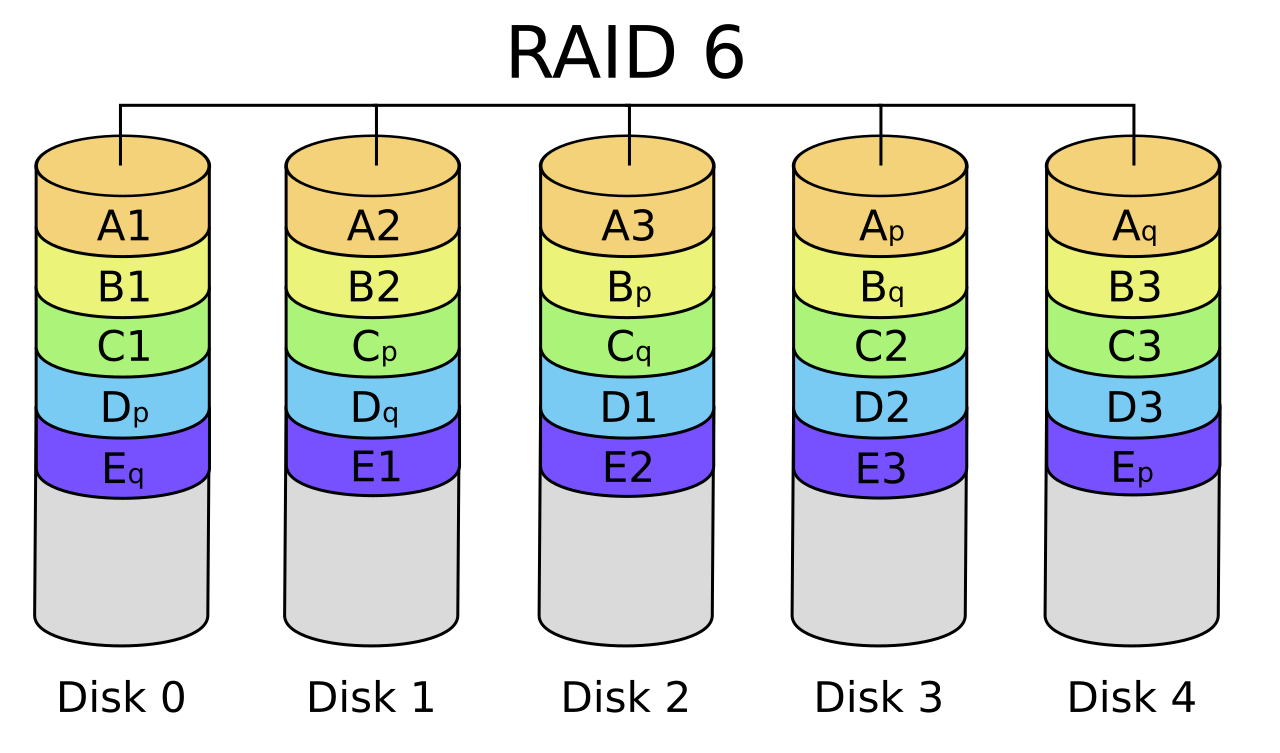
(Source : Wikipedia.org)
Un terme parfois utilisé pour désigner l'implémentation propriétaire du RAID 6 par NetApp est le RAID-DP (Double Parity) -- il s'agit conceptuellement de la même chose, NetApp ayant popularisé cette appellation pour sa technologie à double parité. De manière générale, le concept de double parité correspond au fait de stocker deux jeux d'informations de parité indépendants, ce qui accroît fortement la robustesse du système de stockage en pouvant faire face à deux défaillances simultanées.
RAID 10 (RAID 1+0) : combinaison de miroir et de bandes
Le RAID 10 (dix), parfois noté RAID 1+0, est un niveau RAID imbriqué qui combine les atouts du RAID 1 et du RAID 0. Il nécessite au minimum 4 disques. Le principe est d'abord de former des paires de disques en miroir (RAID 1), puis de répartir (striper) les données entre ces miroirs (RAID 0). Par exemple, avec 4 disques, on a deux miroirs de deux disques chacun, et les données sont écrites par bandes alternées entre les deux miroirs. Ainsi, le RAID 10 offre à la fois la redondance d'un RAID 1 (chaque donnée est dupliquée sur un disque du pair) et les performances du RAID 0 (les lectures/écritures peuvent s'effectuer en parallèle sur les différents miroirs).
En termes de tolérance de panne, le RAID 10 peut supporter la perte d'un disque par paire de miroir. Dans le meilleur des cas, il pourrait tolérer jusqu'à n/2 disques en panne (si chaque miroir n'a qu'un disque défaillant). Cependant, si par malheur les deux disques du même miroir tombent en panne, la grappe est perdue. La probabilité de double panne sur un même miroir est faible, ce qui fait du RAID 10 un système robuste. Sa capacité utile est de 50% (puisque c'est essentiellement du mirroring, la moitié des disques stocke des copies redondantes). Le RAID 10 est souvent prisé pour les bases de données et applications critiques car il conjugue excellente performance (notamment en écriture, pas de calcul de parité) et reconstruction rapide (après une panne, on recopie simplement les données du miroir sain sur un nouveau disque). Son inconvénient principal est le coût en capacité (comme le RAID 1, on « perd » la moitié de l'espace pour la redondance) et le besoin d'un nombre pair de disques.
En variantes de RAID imbriqués, on peut rencontrer aussi le RAID 01 (RAID 0+1, moins courant), le RAID 50 (combinaison de RAID 5 et 0), RAID 60 (RAID 6 et 0), etc., qui cherchent à marier performances et redondance. Ces configurations offrent des compromis spécifiques mais sont plus complexes et s'adressent généralement à des besoins pointus.
RAID-Z (ZFS) : parité adaptative et multiples niveaux
Le RAID-Z est une technologie de redondance propre au système de fichiers ZFS (Sun/Oracle, OpenZFS). Il s'agit d'une variante améliorée du RAID 5, conçue pour tirer parti du modèle copy-on-write de ZFS et éliminer certains écueils du RAID traditionnel (comme le write hole du RAID 5). Dans un pool ZFS, on peut créer des groupes de type raidz1, raidz2 ou raidz3, correspondant respectivement à une parité simple, double ou triple. Autrement dit, un groupe RAID-Z1 tolère 1 panne (analogue RAID 5), un RAID-Z2 tolère 2 pannes (analogue RAID 6 à double parité) et un RAID-Z3 tolère jusqu'à 3 pannes simultanées (triple parité). ZFS est l'un des rares systèmes accessibles au grand public à proposer nativement une triple parité, ce qui vise les très larges baies de stockage professionnelles.
Techniquement, le RAID-Z distribue les données et la (ou les) parité(s) de manière dynamique sur tous les disques du groupe, avec une taille de bande adaptable. Cela signifie qu'il n'y a pas de « taille de stripe » fixe ni de disque de parité dédié : chaque bloc de données écrit occupe n fragments sur n disques et s'accompagne de p blocs de parité (p = 1, 2 ou 3 selon RAID-Z1/2/3). Un avantage majeur est la suppression du risque d'incohérence entre données et parité en cas de coupure de courant (write hole) : grâce au copy-on-write, ZFS n'écrit jamais en place mais toujours dans des blocs neufs, et utilise des checksums pour vérifier l'intégrité. En cas de discordance, ZFS saura quelle copie est correcte. De plus, ZFS effectue des opérations de scrub régulières (vérification intégrale des données et parités) pour détecter et corriger proactivement toute corruption silencieuse. Ce mécanisme permet de résoudre les problèmes de bitrot ou de secteurs illisibles que le RAID classique RAID 5/6 pourrait ne pas détecter.
En contrepartie, le RAID-Z est légèrement moins performant que le RAID classique pour les accès aléatoires de petite taille : chaque I/O tend à mobiliser tous les disques, ce qui limite le parallélisme possible. Les opérations d'écriture, notamment, voient leur IOPS limitées par le disque le plus lent du vdev, puisque chaque écriture implique tous les disques du groupe. En lecture séquentielle de gros blocs en revanche, le RAID-Z s'en tire très bien. ZFS compense aussi par la possibilité d'utiliser la RAM comme cache (ARC) et des SSD dédiés en cache lecture/écriture (L2ARC, ZIL) pour accélérer les performances.
En pratique, on recommande des groupes RAID-Z de 3 à 9 disques pour un bon équilibre performance/efficacité. La capacité utile d'un groupe RAID-Z est d'environ (N -- P) disques (par ex., un raidz2 de 6 disques offre ~4 disques utiles). RAID-Z est très apprécié dans les serveurs de stockage et solutions NAS haut de gamme, car il allie l'intégrité des données (checksums, auto-réparation) à la flexibilité (on peut mélanger des disques de tailles variées sans gâcher d'espace, grâce à la gestion interne de ZFS). On notera que le RAID-Z n'est pas un standard matériel : il est spécifique à ZFS et piloté par le logiciel (ZFS gère lui-même la redondance au niveau du système de fichiers, nous y reviendrons).
Double et triple parité en dehors du RAID-Z
Si ZFS a popularisé la triple parité (RAID-Z3), d'autres systèmes de stockage très haute fiabilité peuvent implémenter des schémas similaires. Par exemple, certains systèmes distribués ou objets utilisent des codes d'effacement (erasure coding) sophistiqués avec plusieurs blocs de parité pour atteindre des niveaux de résilience encore supérieurs (par ex. des stockages cloud qui écrivent k fragments de données + m fragments de parité sur des nœuds différents). Toutefois, dans le cadre des systèmes RAID classiques pour serveurs ou NAS, la double parité (RAID 6) est généralement le maximum disponible sur les contrôleurs RAID du marché. La triple parité reste relativement rare hors ZFS, bien que des solutions comme Microsoft Storage Spaces proposent des options de redondance équivalentes (ex. un three-way mirror est une triple copie, différent de la triple parité mathématique mais visant le même objectif de tolérer 3 pannes). En somme, retenir que :
- Miroir = on stocke des copies identiques (tolérance = perdre tous sauf un disque).
- Parité simple = on stocke une information de parité (tolérance = 1 disque perdu).
- Double parité = deux parités indépendantes (tolérance = 2 disques perdus).
- Triple parité = trois parités (tolérance = 3 disques perdus).
Plus le niveau de redondance est élevé, plus la complexité et le coût en espace augmentent. Le choix dépend donc du niveau de sécurité recherché face aux pannes multiples, en tenant compte de la probabilité de défaillances concomitantes et du temps de restauration.
Redondance et systèmes de fichiers (ZFS, Btrfs, ext4, NTFS, XFS, APFS...)
Après avoir exploré les différentes approches de redondance (miroirs, parités, RAID classiques et variantes), intéressons-nous à la façon dont elles sont prises en charge selon les systèmes de fichiers utilisés. En effet, tous les systèmes de fichiers ne gèrent pas la redondance de la même manière :
- Certains, de conception récente, intègrent nativement des fonctionnalités de RAID ou de multi-disques (c'est le cas de ZFS ou Btrfs notamment). Ces systèmes de fichiers combinent le rôle traditionnel du gestionnaire de volumes et du RAID avec celui du FS, offrant une solution « tout-en-un » pour la redondance, la gestion de l'intégrité et les fonctionnalités avancées (snapshots, etc.).
- D'autres, plus classiques (comme ext4, XFS ou NTFS), ne prévoient aucune redondance interne : ils fonctionnent sur une seule unité de stockage à la fois. Pour obtenir de la redondance avec ces FS, il faut donc recourir à une couche supplémentaire, par exemple un RAID matériel (contrôleur dédié) ou un RAID logiciel du système d'exploitation (mdadm/LVM sous Linux, "disques dynamiques" ou Storage Spaces sous Windows, AppleRAID sous macOS, etc.). Le système de fichiers lui-même est alors ignorant de la redondance : il voit un volume logique déjà fiabilisé par en dessous.
Nous allons passer en revue chaque système cité et décrire son approche vis-à-vis de la redondance des données.
ZFS : redondance intégrée (RAID-Z, miroirs et auto-réparation)
ZFS (Zettabyte File System) est un système de fichiers révolutionnaire créé par Sun Microsystems, combinant un système de fichiers haute intégrité et un gestionnaire de volumes. ZFS a été conçu dès l'origine pour intégrer la gestion de multiples disques avec redondance, sans nécessiter de RAID matériel. Un pool ZFS peut être configuré avec différents vdevs redondants : miroirs (copies multiples) ou RAID-Z de niveau 1, 2 ou 3 parité(s) comme vu précédemment. Ainsi, ZFS offre en natif les équivalents des RAID 1, 5, 6 (et au-delà).
L'implémentation de ZFS apporte plusieurs avantages clés : d'une part, l'intégrité des données est assurée par des sommets de contrôle (checksums) sur chaque bloc. A chaque lecture, ZFS vérifie le checksum ; si un bloc s'avère corrompu (par exemple à cause d'un bit altéré sur le disque), ZFS le détecte et peut automatiquement le corriger en allant chercher une copie saine de la donnée (sur l'autre disque du miroir, ou en recomposant via la parité RAID-Z). Ce mécanisme d'auto-réparation fait de ZFS un champion de la lutte contre la corruption silencieuse.
D'autre part, ZFS évite le problème du RAID classique appelé write hole : grâce à sa nature transactionnelle (copy-on-write), il n'y a jamais de désynchronisation possible entre la parité et les données -- on n'écrit les nouvelles données et parités qu'une fois l'opération finalisée en mémoire, garantissant la cohérence. ZFS permet également des fonctions avancées comme les instantanés (snapshots), la compression transparente, la déduplication et le chiffrement (selon versions), sans oublier une extensibilité massive (adresses 128 bits). Tout cela a un coût : ZFS est relativement gourmand en RAM et plus complexe à administrer qu'un FS traditionnel. En contrepartie, il fournit une solution de stockage complète où la redondance est traitée au niveau du système de fichiers lui-même. En somme, ZFS offre le plus haut niveau de redondance et d'intégrité, au point d'être souvent utilisé dans les serveurs de stockage critiques. Comme l'affirment de nombreux experts, ZFS se distingue par une fiabilité extrême, avec redondance intégrée et corrections automatiques des erreurs.
Btrfs : RAID logiciel intégré et flexibilité
Btrfs (B-Tree File System), apparu en 2009, est l'équivalent Linux « grand public » le plus proche de ZFS en termes de fonctionnalités. Il a été conçu pour apporter au kernel Linux des fonctionnalités avancées : copy-on-write, snapshots, sous-volumes, vérification d'intégrité par checksums, et effectivement la gestion de la redondance sur plusieurs disques. Btrfs intègre en natif un gestionnaire de volumes multi-disques et supporte plusieurs profils de stockage : striping (raid0), mirroring (raid1, raid1c3/raid1c4 pour 3 ou 4 copies), et la parité (raid5, raid6). Cela signifie qu'un volume Btrfs peut être créé directement sur, par exemple, 3 disques en RAID5, sans avoir besoin de configurer un mdadm en dessous -- Btrfs s'occupe lui-même de dispatcher les données et calculer les parités. De même, on peut faire un Btrfs en RAID1 sur 2 disques, ou en RAID10 sur 4 disques, etc., par de simples options de montage/formatage.
Btrfs offre également des fonctions de scrub (vérification des checksums sur disque, correction via copies redondantes) et de self-healing similaires à ZFS. Par exemple, si un bloc est lu avec une erreur et qu'une autre copie existe intègre, Btrfs pourra le détecter et remplacer le bloc corrompu automatiquement. Ces capacités font de Btrfs un système orienté tolérance aux pannes et à la corruption, largement supérieur en cela aux ext4/XFS traditionnels.
Néanmoins, Btrfs n'est pas sans quelques réserves. Historiquement, son implémentation du RAID5/6 a été jugée peu mature et sujette à un write hole (car Btrfs n'est pas transactionnel au niveau des parités comme ZFS). Pendant longtemps, l'utilisation de Btrfs en mode RAID5/6 a été découragée en production, les développeurs le marquant comme « instable » et à réserver aux tests. Des efforts sont en cours pour améliorer cela, mais en 2025 encore, il est recommandé d'être prudent avec Btrfs RAID5/6 sur des données critiques. En revanche, les modes sans parité (RAID1, RAID10, ou le mode RAID1 à 3 ou 4 copies introduit récemment) sont considérés comme stables et robustes. Btrfs offre même des variantes RAID1 élargies (par exemple on peut faire un RAID1 sur 3 disques où chaque donnée est présente sur 2 des 3 disques, ou sur 4 disques avec 2 copies, etc., ce qui s'approche d'un compromis entre RAID1 et RAID5).
En somme, Btrfs se positionne comme un compromis entre ext4 et ZFS : il apporte la redondance intégrée (RAID logiciel) et des fonctionnalités de pointe (snapshots, intégrité, compression), tout en étant plus léger que ZFS. Sa souplesse (par ex. on peut ajouter/supprimer des disques au volume à la volée, rebalancer les données etc.) en fait un choix populaire pour des serveurs domestiques ou petites infrastructures. Toutefois, pour les besoins critiques où la parité est nécessaire, beaucoup considèrent encore ZFS plus éprouvé que Btrfs, ce dernier étant parfois qualifié de "technologie encore en évolution". Btrfs convient très bien pour du RAID1/10 fiable et performant, ou pour des systèmes de fichiers sur un seul disque profitant des snapshots et de la déduplication, mais son RAID5/6 natif attend d'être pleinement fiabilisé (des distributions comme Synology l'autorisent en l'encapsulant sur du RAID Linux mdadm pour plus de sécurité).
ext4 : pas de redondance native (dépend du RAID sous-jacent)
Ext4 est le système de fichiers par défaut de la majorité des distributions Linux depuis la fin des années 2000. Il s'agit d'un système monodisque classique (évolution de ext3/ext2) qui n'embarque aucune fonctionnalité de gestion de multiples périphériques. Ext4 excelle en stabilité et performances, mais il ne possède pas de mécanisme de redondance interne. Si on souhaite de la tolérance de panne avec ext4, on doit placer le système de fichiers sur un volume RAID externe. Concrètement, on utilisera soit un RAID logiciel Linux (via mdadm ou LVM en mode RAID), soit un RAID matériel (carte contrôleur dédiée, baie externe), puis on créera la partition ext4 sur ce volume agrégé. Ext4 n'aura alors pas conscience qu'il tourne sur un assemblage redondant, il profitera simplement de la fiabilité apportée par la couche inférieure.
Cette absence de RAID natif est normale car ext4 est antérieur à la vague des systèmes CoW; il s'inscrit dans la philosophie Unix traditionnelle « faire une chose et le faire bien » (ici : être un FS journalisé efficace). Il offre bien la journalisation (journal des métadonnées pour fiabiliser les transactions disque) et quelques protections de base (checksums du journal, duplicatas de super-bloc), mais pas de checksum sur les données, pas de réplication de blocs, etc. En cas de corruption silencieuse ou de bad-block non détecté par le disque, ext4 ne le verra pas. C'est pour cela qu'il est crucial, si ext4 est utilisé sur un RAID matériel/logiciel, de s'assurer que le contrôleur ou la couche RAID gère bien la détection d'erreurs (parité, scrubbing). En pratique, ext4 est souvent utilisé sur des RAIDs matériels de serveurs, lesquels intègrent des caches protégés (batterie BBU) et des routines de vérification en arrière-plan. Sur PC grand public, on peut tout à fait faire un RAID logiciel (mdadm) et y mettre de l'ext4 : Linux supporte les RAID 0/1/5/6/10 en natif via mdadm depuis longtemps, et ext4 fonctionnera dessus sans problème.
En résumé, ext4 ne supporte pas le RAID "out of the box" : il faut un gestionnaire de RAID externe. Cette modularité a l'avantage de la souplesse (on peut choisir n'importe quel niveau RAID sous-jacent), et ext4 reste aujourd'hui l'un des FS les plus éprouvés et performants pour un usage standard. Mais pour des besoins d'intégrité avancée ou d'administration facilitée de la redondance, des FS plus modernes comme ZFS/Btrfs apportent des garanties supplémentaires que ext4 seul ne fournit pas.
XFS : pas de redondance native non plus
XFS est un autre système de fichiers Linux populaire, particulièrement adapté aux grandes tailles et aux hautes performances en I/O séquentielles. Comme ext4, XFS est un FS journalisé classique sans fonctionnalité RAID intégrée. Il a été développé par SGI dans les années 90 pour des systèmes haute performance, et il n'implémente pas de gestion multi-disques en interne. Donc, tout comme ext4, un volume XFS couvre une seule unité de stockage. Pour la redondance, XFS doit être déployé sur une solution RAID externe (mdadm, LVM-raid, RAID matériel).
XFS présente tout de même quelques caractéristiques particulières relatives aux environnements RAID : par exemple, il est recommandé de bien aligner la taille de bande (stripe unit/width) d'un XFS sur un RAID 5/6 afin d'optimiser les accès, et XFS peut détecter certaines incohérences de géométrie si on modifie la grappe RAID sous-jacente (comme un reshape). Mais ça reste du domaine du réglage : XFS ne reconstruit pas de données tout seul, il ne sait que travailler avec ce que le bloc device lui présente.
Niveau intégrité, XFS inclut depuis quelques années des checksums sur ses métadonnées (comme ext4 le fait également), pour s'assurer de la cohérence interne. Cependant, il ne calcule pas de somme de contrôle sur les données utilisateur, pas plus qu'il n'a de copies multiples. Il dépend donc, pour la fiabilité, du matériel (disques) et éventuellement du RAID en dessous pour éviter les pertes. XFS a la réputation d'être très robuste et performant pour les très gros volumes (jusqu'à 8 exabytes) et les fichiers de grande taille, et est souvent utilisé avec du RAID matériel dans les serveurs de stockage, notamment en environnement SAN. Son absence de redondance native n'est pas un handicap dans ces contextes, car on préfère souvent un contrôle matériel dédié (contrôleur RAID) gérant la redondance, tandis que XFS se concentre sur la rapidité du système de fichiers.
En somme, XFS est à mettre dans le même sac que ext4 pour ce qui concerne la redondance : pas gérée en interne. On compte sur un niveau inférieur pour fournir la tolérance aux pannes. D'ailleurs, dans un comparatif, ext4 et XFS ne supportent pas le RAID en natif, contrairement à Btrfs et ZFS qui l'intègrent. Ce choix d'architecture est cohérent avec l'époque de conception de XFS (milieu 90s), où le RAID hardware était la norme pour la redondance.
NTFS : pas de redondance intégrée sous Windows
NTFS (New Technology File System) est le système de fichiers principal de Windows depuis plus de 20 ans. Du point de vue de la redondance, NTFS est similaire à ext4/XFS : il ne propose pas de RAID ou de duplication de données au niveau du système de fichiers lui-même. La haute disponibilité sous Windows s'appuie traditionnellement sur d'autres mécanismes :
- RAID logiciel Windows : Les versions professionnelles de Windows ont historiquement offert la gestion de volumes en miroir (RAID 1) ou agrégés (RAID 0) via les disques dynamiques. Windows 2000/2003 permettait même la création de volumes RAID 5 (parité) en logiciel, bien que cette fonctionnalité ait toujours été limitée (et supprimée dans les OS clients récents). Aujourd'hui, Microsoft propose les "Storage Spaces" (Espaces de stockage) introduits avec Windows 8/10, qui offrent des fonctionnalités de mise en pool de disques avec options de redondance : simple (pas de redondance), two-way mirror (équivalent RAID 1), three-way mirror (trois copies), ou parité (équivalent RAID 5) et double parité (équivalent RAID 6). Ces espaces de stockage fonctionnent en dessous du système de fichiers (NTFS ou ReFS), un peu à la manière de mdadm sur Linux. NTFS n'est pas au courant de la redondance, c'est Storage Spaces qui assure que les écritures sont dupliquées ou que la parité est calculée sur plusieurs disques.
- RAID matériel : Comme ailleurs, on peut utiliser un contrôleur RAID matériel sous Windows (par exemple une carte RAID PCIe, ou un contrôleur intégré sur une carte-mère) pour présenter à Windows un volume redondé. NTFS y sera créé et se comportera normalement. Windows n'y verra que du feu (le RAID est transparent pour lui).
En résumé, NTFS dépend entièrement de solutions externes pour la redondance, exactement comme ext4 ou XFS. Il convient de mentionner que Microsoft a développé un système de fichiers plus récent nommé ReFS (Resilient File System), introduit avec Windows Server 2012 et Windows 10, qui vise une meilleure résilience. ReFS, couplé aux Storage Spaces, est capable de détecter la corruption via des checksums (métadonnées et optionnellement données utilisateur) et de recréer des données corrompues à partir des copies redondantes, un peu à la manière de ZFS/Btrfs. Cependant, ReFS n'est généralement pas utilisé sur les postes clients et reste réservé à certains usages serveurs. Sur la plupart des stations et serveurs Windows classiques en 2025, c'est toujours NTFS sur du RAID matériel ou Storage Spaces qui fournit la redondance.
À noter également : NTFS a une fonctionnalité dite "self-healing" dans Windows (introduite avec Windows Vista) qui peut réparer automatiquement certaines erreurs mineures du système de fichiers en arrière-plan, mais cela n'a rien à voir avec de la redondance multi-disque ; c'est juste de la réparation logique locale. Pour la tolérance de panne disque, Windows compte sur le miroir ou la parité fournis en dessous. En conclusion, NTFS ne gère pas de RAID en natif (pas de "Built-in RAID") : on utilisera les disques dynamiques/Storage Spaces pour du RAID logiciel, ou du RAID matériel. Le choix dépendra des besoins (coût, performance, flexibilité) et de la version de Windows (les Storage Spaces étant la solution moderne recommandée par Microsoft sur les OS récents).
APFS : redondance multi-disque via Apple RAID (pas de parité native)
APFS (Apple File System) est le système de fichiers introduit par Apple à partir de macOS High Sierra (10.13) pour remplacer HFS+. Conçu pour les SSD, APFS apporte des fonctionnalités modernes (snapshots, clones, chiffrement, partage d'espace entre volumes, etc.), mais la gestion de la redondance multi-disque n'est pas intégrée directement dans APFS. En environnement macOS, la redondance passe par des solutions distinctes, en particulier l'Apple RAID logiciel disponible via l'Utilitaire de disque (ou la ligne de commande diskutil). Apple RAID permet de créer des ensembles RAID 0 (agrégat par bandes), RAID 1 (miroir) ou JBOD (concaténation) au niveau bloc. APFS peut ensuite être utilisé sur de tels ensembles sans problème -- en fait APFS voit l'ensemble comme un seul disque logique.
Apple a documenté ceci clairement : « Apple File System ne met pas en œuvre directement de RAID logiciel; cependant, on peut combiner des volumes formatés APFS avec un volume Apple RAID pour prendre en charge le striping (RAID 0), le mirroring (RAID 1) et la concaténation (JBOD). Les volumes APFS peuvent aussi être utilisés avec des solutions RAID matérielles directes ». Cela signifie qu'un utilisateur Mac qui souhaite, par exemple, un miroir de deux SSD en APFS devra d'abord créer un RAID 1 Apple avec ses deux disques (via l'Utilitaire de disque ou diskutil appleRAID), puis formater le résultat en APFS. Inversement, on peut faire un RAID 0 de deux disques et y mettre APFS pour augmenter les performances, mais là encore sans redondance. Apple RAID (logiciel) ne supporte pas les niveaux à parité (RAID 5) ; pour cela il faudrait recourir à des solutions tierces (comme SoftRAID) ou un boîtier RAID matériel -- APFS fonctionnera alors sur ce volume RAID comme n'importe quel FS.
Il est intéressant de noter qu'APFS apporte une forme de redondance interne pour la fiabilité, mais limitée aux métadonnées : il garde plusieurs copies de certains metadata critiques sur le même disque (ce que HFS+ appelait les "Spare sectors") afin de pouvoir reconstruire la structure du FS en cas de corruption localisée. Cependant, APFS n'effectue pas de duplication des données utilisateurs ni de calcul de parité interne. C'est un FS prévu pour une utilisation sur un seul disque ou un seul conteneur logique. Apple mise davantage sur la gestion logicielle au niveau OS pour la redondance (notamment via Time Machine pour la sauvegarde, ou l'usage de leur système de clustering Xsan pour les besoins professionnels).
En somme, APFS n'a pas de RAID natif. Sur macOS, si l'on veut de la tolérance aux pannes, il faut utiliser soit un RAID matériel (ex. un boîtier Thunderbolt RAID qui présente un volume protégé), soit l'AppleRAID logiciel (limité à RAID 0/1) avant d'appliquer APFS. Cette situation est similaire à NTFS/Windows ou ext4/Linux en l'absence de ZFS/Btrfs. Il est à noter que macOS gère le RAID logiciel 0/1 depuis longtemps (déjà sous Mac OS X on pouvait faire des RAID via l'Utilitaire de disque), mais Apple ne propose toujours pas de solution grand public pour du RAID 5 en natif (probablement en raison de la complexité et des performances médiocres du RAID 5 logiciel sans cache, et du fait qu'Apple privilégie la simplicité pour l'utilisateur). Pour des besoins de RAID 5 sur Mac, il faut généralement investir dans un boîtier RAID matériel ou un logiciel spécialisé.
En résumé, APFS se concentre sur d'autres aspects (sécurité, snapshots, efficacité sur SSD) et laisse la redondance multi-disque à d'autres couches. Un volume APFS peut tout à fait résider sur un ensemble RAID 1 ou 0, mais APFS lui-même ne saura pas recréer un bloc perdu sans aide du dessous. Apple résume cela ainsi dans sa FAQ développeur : « APFS ne propose pas de RAID logiciel, mais fonctionne avec Apple RAID ou du RAID matériel ».
Tableaux comparatifs des approches de redondance
Pour conclure, voici deux tableaux synthétiques qui comparent les différentes approches de redondance entre elles, ainsi que le support de ces approches selon les systèmes de fichiers.
Comparaison des principaux niveaux de RAID
Le tableau suivant résume les caractéristiques des principaux niveaux de RAID courants (et assimilés), en termes de tolérance de panne, overhead de stockage, impact sur les performances et complexité de mise en œuvre.
📥 Télécharger comparatifs-redondance.pdf
Légende : Tolérance indique le nombre de disques pouvant tomber en panne sans perte de données. Capacité utile exprime l'espace utilisable par rapport au total brut. Impact performances est schématisé en termes de tendance générale (+ amélioration, -- dégradation). Complexité est une évaluation qualitative de la difficulté de configuration/maintenance.
Support de la redondance selon les systèmes de fichiers
Le tableau suivant récapitule, pour chaque système de fichiers courant, s'il prend en charge la redondance nativement et sous quelle forme :
📥 Télécharger comparatifs-fs.pdf
(Les trois derniers exemples sont hors sujet du stockage local classique, mais illustrent d'autres approches de redondance dans des contextes spécifiques.)
Comme on le voit, seuls certains systèmes de fichiers de nouvelle génération intègrent directement la gestion de la redondance (ZFS, Btrfs). Ceux-ci se comportent en fait comme des gestionnaires de volumes et de RAID en plus d'être des FS, offrant une solution complète mais au prix d'une complexité accrue. Les systèmes de fichiers plus traditionnels (ext4, XFS, NTFS, APFS) s'en remettent à la couche sous-jacente pour la redondance : soit au matériel, soit à une couche logicielle de l'OS. Il n'y a pas de "meilleur" choix universel, tout dépend du contexte :
- Pour un serveur critique où l'intégrité prime, ZFS est souvent plébiscité grâce à ses multiples parités et sa réparation automatique.
- Pour un NAS domestique avec 2 à 4 disques, Btrfs en miroir peut offrir un bon compromis (snapshots et simplicité d'administration), à condition d'éviter le RAID5/6 encore expérimental.
- Dans un environnement Windows, l'utilisateur se reposera sur les Storage Spaces ou un RAID matériel, car ni NTFS ni ReFS ne font de RAID par eux-mêmes.
- En entreprise, si on dispose de bons contrôleurs RAID matériels, on continuera d'utiliser ext4 ou XFS sur ces contrôleurs, ceux-ci assurant la redondance de façon transparente.
Synthèse finale
La redondance des données est un pilier de la sécurité en stockage : elle permet de tolérer la panne de supports sans interruption de service ni perte d'informations, ce qui est crucial tant pour les serveurs professionnels que pour les NAS grand public. Nous avons exploré les différentes techniques disponibles, du simple miroir (RAID 1) aux schémas à parité complexe (RAID 5/6, RAID-Z), en passant par les combinaisons hybrides (RAID 10) et les innovations logicielles apportées par des systèmes de fichiers modernes (ZFS, Btrfs). Chaque approche a ses avantages et inconvénients : niveau de protection plus ou moins élevé, coût en capacité (du 50% pour un miroir à ~80% pour du RAID 5, etc.), impact sur les performances (la parité induit une charge de calcul en écriture), et complexité de mise en œuvre (un RAID matériel masque la complexité au système d'exploitation, là où un ZFS requiert de maîtriser sa configuration logicielle).
Il est important de choisir la solution de redondance en fonction des besoins réels et des contraintes : par exemple, un RAID 6 est indiqué pour une grande grappe de disques durs afin de prévenir la double panne, alors qu'un miroir simple peut suffire pour un petit serveur nécessitant surtout de la simplicité. De même, opter pour un système de fichiers comme ZFS ou Btrfs peut apporter un niveau de protection supérieur (détection de la moindre corruption et auto-guérison) au prix d'une utilisation plus exigeante en ressources, là où un ext4 sur RAID matériel sera très performant et suffisant dans bien des cas si l'on a par ailleurs une bonne politique de sauvegardes.
Justement, rappelons en dernier point que la redondance ne remplace pas la sauvegarde.
Un RAID, aussi sophistiqué soit-il, protège contre la défaillance matérielle d'un disque, mais ne met pas vos données à l'abri d'une suppression accidentelle, d'un ransomware, d'une corruption logique ou d'une catastrophe physique (incendie, vol de la machine...). Il faut donc voir la redondance comme une assurance disponibilité (le service continue malgré une panne de disque) et non comme une garantie absolue d'intégrité dans tous les cas de figure. L'idéal est de combiner un système de stockage redondant pour la tolérance de panne et une stratégie de sauvegardes externes pour pouvoir restaurer les données en cas de problème non couvert par la redondance.
En résumé, nous disposons aujourd'hui d'un large éventail de solutions pour éviter que la panne d'un disque dur ne se solde par une perte de données. Des technologies historiques comme le RAID aux solutions logicielles intégrées des systèmes de fichiers modernes, il est possible d'adapter le niveau de redondance au niveau de risque acceptable. À vous, en tant qu'Administrateur, de déterminer la configuration optimale en tenant compte du triptyque : sécurité des données, performances et coût/complexité. Avec les connaissances approfondies exposées dans ce cours, vous êtes désormais armé pour faire ces choix de manière éclairée et assurer une conservation pérenne de vos précieuses données.